Engineering Blog - Prexy: supersnelle zoek- en vervangregels
Delen
Welkom bij ons eerste engineering blog. Het zit wellicht wat technischer in elkaar dan je gewend bent van de andere blogs, maar we hebben ons best gedaan om het voor iedereen begrijpbaar te maken. In dit artikel gaan we het hebben over Prexy, een nieuw stuk software binnen Clonable dat gebruikt wordt voor het toepassen van de substitution rules.
Achtergrond
Als gebruiker van Clonable ken je de substitution rule functionaliteit misschien al. Deze zoek- en vervangregels kun je gebruiken om stukken tekst of code uit te wisselen met een zelfgekozen variant. Dit kun je bijvoorbeeld gebruiken om een API key te vervangen of een analytics ID zodat je verschillende analyses kunt maken voor je originele site en je vertaalde clones. Intern worden deze zelfde regels ook gebruikt voor het vervangen van je originele domeinnaam naar de domeinnaam van je clone en een aantal andere zaken.
Sinds de allereerste versie van Clonable is deze functionaliteit nooit aangepast, en dat is op zich niet gek, want het het deed prima zijn werk. Toch waren er wel verbeteringen mogelijk, zowel op het gebied van performance als op het gebied van gebruiksvriendelijkheid. Eens in de zoveel tijd pakken we Clonable een stuk van ons product waar al lang geen tijd meer aan is besteed om dit te gaan verbeteren. Zo hebben we vorig jaar heel onze data-infrastructuur herzien om deze sneller, schaalbaarder, en fout-toleranter te maken, en hebben we daarvoor ook al eens de URL-vertaling functionaliteit vanaf de grond af aan opnieuw opgebouwd. Dit kwartaal was het de beurt aan de substitution regels.
Oude situatie en beperkingen
Substitution regels worden bij Clonable pas in de allerlaatste fase toegepast, net voor het terugsturen van de response naar de client. Bij de eerste versie van Clonable is er daarom voor gekozen om dit te implementeren binnen de webserver NGINX met behulp van replace-filter-nginx-module, een module gemaakt door OpenResty. De module gebruikt sregex als streaming regex engine, tevens gemaakt door OpenResty. Het streamende aspect is belangrijk in dit geval, omdat we niet elke response volledig in het geheugen willen laden. Wanneer we dit wel zouden doen, zouden een aantal grote responses ervoor kunnen zorgen dat NGINX crasht of vastloopt omdat er onvoldoende geheugen beschikbaar is. Een tweede belangrijk kenmerk van sregex, is dat deze meerdere regels in parallel kan vewerken. Elke clone heeft namelijk al een aantal standaardregels en daarnaast soms een aantal regels die specifiek voor de clone zijn toegevoegd. Als deze niet tegelijkertijd behandeld zouden kunnen worden, zouden we alsnog de gehele response moeten bufferen, omdat we er na de eerste regel nog een keer overeen moeten kunnen lopen voor de tweede regel.
Afgelopen jaar kwamen we echter steeds vaker vreemde performanceproblemen tegen. Deze problemen waren vaak van korte duur, maar konden de responsetijd van een pagina in extreme gevallen seconden langer maken. Na één zo'n piek laadde de pagina vaak weer normaal, wat het probleem moeilijk te reproduceren was. Om dit verder te debuggen hebben we de Clonable-Timings header toegevoegd aan alle responses, wat ons in staat stelde om in grove lijnen te bepalen welke stap van het vertaalproces zo veel tijd in beslag nam. Hieruit kwam naar voren dat in bijna alle gevallen de upstream snel reageerde, en dat ook het vertalen vrij vlot ging. Er zat echter een gat tussen het afronden van de vertaling en het volledig afronden van de request en dit gaf ons een hint dat het met de substitution regels te maken zou kunnen hebben.
Het concurrency model van NGINX
Dit gaf ons echter nog geen antwoord op de vraag waarom deze vertragingen slechts sporadisch optraden, en waarom dit gebeurde terwijl de servers nog niet eens voor de helft van hun capaciteit belast werden. Om dit fenomeen beter te begrijpen, moeten we wat dieper kijken in hoe NGINX workloads afhandelt.
NGINX heeft een worker-architectuur met één master process en meerdere worker processes. Verbindingen worden verdeeld over de workers om zo meerdere requests tegelijkertijd te kunnen verwerken. Deze set-up heeft echter ook een nadeel: wanneer een worker druk is met het verwerken van een request, moeten de andere requests die ook zijn toegewezen aan diezelfde worker wachten. Dit kan ervoor zorgen dat één zwaar request kan zorgen voor vertraging bij meerdere requests, zelfs als de andere workers niets te doen hebben. Dit effect is goed te zijn in onderstaande afbeelding. Tijdens het maken van deze afbeelding loopt er een stresstest over 10 verschillende verbindingen. In de afbeelding is vervolgens duidelijk te zien dat er 3 workers druk bezig zijn, en een vierde bijna niets doet.

Tijd voor Prexy
Met de bottleneck duidelijk zichtbaar, maakten we een plan om dit te verbeteren. Dit project kreeg de naam Prexy, een samenvoeging van RegEx en Proxy. Er waren 3 hoofdeisen aan het eindresultaat:
Het moet een drop-in replacement zijn voor de huidige set-up. De substitution regels moeten op dezelfde manier worden toegepast om te voorkomen dat er dingen stuk gaan in bestaande setups.
De substitution rules moeten streamend worden toegepast om te voorkomen dat de oplossing te veel geheugen gebruikt.
De nieuwe oplossing moet sneller zijn dan de huidige oplossing.
Als eerste moesten we op zoek naar een krachtige multi-threaded runtime die requests op een efficiënte manier kan verwerken. Na meerdere opties te hebben overwogen landde de keuze op de Tokio runtime voor de programmeertaal Rust. Rust staat erom bekend dat je er snelle programma's mee kunt schrijven, zonder de safety-risico's van andere low-level talen zoals C++. De Tokio runtime is een flexibele asynchronous runtime gemaakt voor netwerkapplicaties. Eén van de belangrijkste functies voor ons is het feit dat hij work-stealing is. Dit houdt in dat, in tegenstelling tot NGINX, een request niet gebonden is aan één worker, maar dat een worker die niets te doen heeft werk kan “stelen” van een andere worker. Op die manier kunnen de resources van onze servers beter benut worden.
Eerste prototype
Na het kiezen van de onderliggende technologieën, besloten we een eerste prototype op te zetten om in te schatten hoeveel snelheidswinst dit project ons ongeveer zou opleveren en of het überhaupt de moeite waard was. Als eerste implementatie voor de regex engine (het gedeelte dat daadwerkelijk de regels verwerkt en toepast), gebruikten we de standaard regex library (of crate zoals ze in Rust-terminologie worden genoemd). Deze engine is, net als sregex, non-backtracking, wat betekent dat minder risico loopt op een ReDoS issue. Bij een ReDoS krijgt een regular expression met een dusdanige input te maken, dat de tijd die het kost om de input te evalueren exponentieel stijgt. Dit kan desastreus zijn voor de performance, en heeft er bij cloudflare voor gezorgd dat ze een flinke storing hadden. Voor ons is het dus van belang dat de engine die we gebruiken non-backtracking is.
Met deze regex engine bouwden we een eerste prototype. Dit prototype gebruikte hard-coded regels en de regex engine bufferde de gehele response in plaats van hem te streamen, maar dit was genoeg voor een eerste performance test.
Met deze regex engine bouwden we een eerste prototype. Dit prototype gebruikte hard-coded regels en de regex engine bufferde de gehele response in plaats van hem te streamen, maar dit was genoeg voor een eerste performance test. Onze test-setup bestond uit twee VMs. Op de ene VM draaide een setup waarin zowel de oude oplossing als de nieuwe oplossing op konden draaien. Op die manier konden we eenvoudig vergelijkingen maken tussen beide methodes. Op de andere server draaide NGINX die dienst deed als origin server en een testbestand serveerde. Op diezelfde server draaide ook de tool wrk, waarmee we de load genereerden. Helemaal optimaal is dit niet, aangezien je voor zuivere data het liefste de load generator op een aparte VM wilt draaien, maar deze VM had genoeg resources zodat NGINX en wrk elkaar niet in de weg zaten.
De eerste testresultaten waren overduidelijk: Prexy was ongeveer 22 keer zo snel in het behandelen van één request (zie de afbeelding hieronder). Dit gaf het project definitief groen licht, omdat er met zo'n groot verschil genoeg ruimte was om wat performance degradaties te incasseren die zich eventueel voor zouden doen met het volledig maken van de functionaliteit.

Na de eerste test voerden we een aantal voor de hand liggende optimalisaties door, zoals het cachen van gecompilede regular expressions. Daarnaast implementeerden we een efficiëntere manier om verbindingen naar de upstream te hergebruiken. Hiermee behaalden we een snelheidswinst van zo'n 20%. We testten toen ook beide oplossingen onder piekbelasting, waarbij we zoveel mogelijk requests naar de server stuurden. Ook hier was het verschil goed zichtbaar en behaalde Prexy een throughput van ongeveer 25x zo hoog als de oude oplossing.
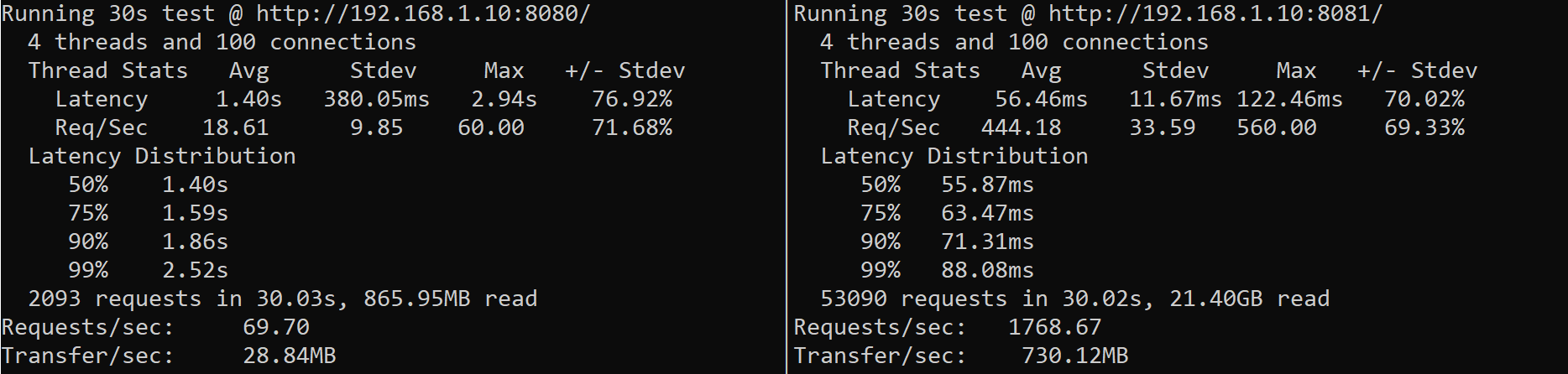
Streaming regex engine
Een van de eisen van dit project was dat de regex engine die gebruikt wordt streaming is. De regex create van het prototype is dat niet, dus op dit vlak was nog extra werk nodig. De regex crate bleek echter wel zeer geoptimaliseerd te zijn, dus we besloten om deze implementatie wel als basis te nemen voor onze streaming engine. Wanneer je data door een regex engine streamt zijn er een aantal zaken belangrijk om in de gaten te houden. Ten eerste weet je niet welke data er nog gaat komen. Je moet daarom gaan werken met gedeeltelijke matches: matches die nog niet compleet zijn, maar al wel 1 of meer karakters hebben gematcht. Bij het vinden van een complete match moet er vervolgens gecontroleerd worden dat er geen overlappende gedeeltelijke matches zijn, omdat deze uiteindelijk ook nog kunnen matches (en een langere match wint van een kortere match in het geval van overlap). Je kunt dus pas een match gaan verwerken als alle op dat moment gedeeltelijke matches geen volledige match blijken te zijn.
Verdere optimalisaties
Het ombouwen van de regex engine had, zoals verwacht, een negatieve impact op de prestaties van Prexy. Er was echter nog steeds genoeg marge vergeleken met de oude oplossing en door het toevoegen van verdere optimalisaties kwamen we uiteindelijk zelfs weer hoger uit dan voor het ombouwen van de regex engine. Eén van de optimalisaties die we toepasten was het onthouden of een regel toegepast moet worden op een bepaald bestand. Statische assets zoals CSS en JS bestanden veranderen bijna nooit en daarvoor is het nutteloos om telkens een regel uit te voeren terwijl deze nooit matcht op dat specifieke bestand. Een alternatief hiervoor was om het resultaat van de vervangingen te cachen, maar het nadeel van deze strategie is dat het veel geheugen kost om alle bestanden in op te slaan. Door te onthouden welke regels toegepast moeten worden hebben we maar een paar bytes nodig per bestand door de informatie op te slaan als een bitmap.
Daarnaast maken we optimaal gebruik van optimalisaties binnen de regex engine door bijvoorbeeld capturing groups niet bij te houden wanneer deze niet gebruikt worden in de vervanging. Hierdoor hoeft de regex engine alleen het begin en einde van de gehele match te onthouden en dat scheelt werk. Ook hebben we named capturing groups uitgeschakeld, omdat dit in de streamende variant best complex was en omdat de oude oplossing dat ook niet ondersteunde was dit ook niet per sé nodig. Al deze optimalisaties zorgden uiteindelijk voor de volgende prestaties:
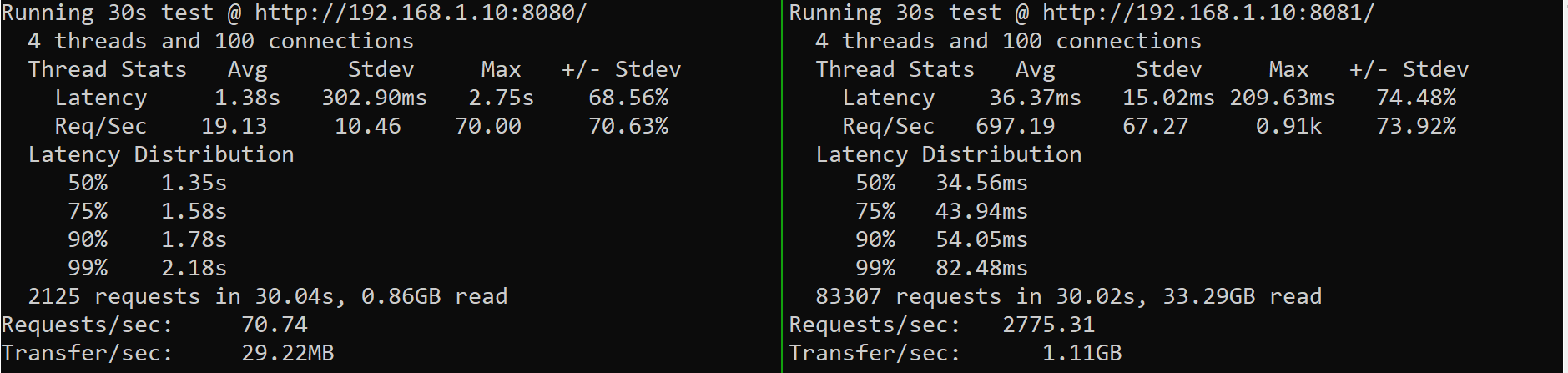
Het eindresultaat
Na het uitvoerig testen van Prexy om te zorgen dat het gedrag inderdaad hetzelfde was als de oude oplossing, begonnen we met het stapsgewijs uitrollen. Over een periode van ongeveer een week hebben we voor iedere clone Prexy geactiveerd. In onze monitoring was het moment van activatie vaak goed te zien. Een afname van ongeveer 50% bij de responsetijden was niet zeldzaam om te zien. Er waren ook minder grote verschillen van ongeveer 10% te zien bij andere klanten die maar weinig substitution regels hadden. Onze eigen website werd ongeveer 30% sneller (~50ms).
Over onze algehele infrastructuur zien we de volgende verschillen na het uitrollen van Prexy.
33% minder RAM-verbruik
20% minder CPU-verbruik
10-50 % snellere responses
Al met al kunnen we dus stellen dat Prexy een succesvol project was. Door het vervangen van een verouderde NGINX module kunnen we nu gebruik maken van nieuwere en efficiëntere technieken die een duidelijk meetbaar verschil maken voor al onze klanten. Ook in de toekomst zullen we bezig blijven met het verbeteren van Clonable, zowel op het gebied van nieuwe functies als het verbeteren van bestaande functionaliteit.
Bedankt voor het lezen van deze engineering blog. Laat het ons weten als je het leuk vindt om vaker dit soort technische inkijkjes te krijgen in ons product. Ben je helemaal enthousiast geworden van dit project? Kijk dan ook eens op onze vacaturepagina :)